
ORB-SLAM3 on iPhone
ORB-SLAM3 is a state-of-the-art visual SLAM. This feature-based SLAM creates a sparse mapping and gives accurate localization. Also, it contains modules such as place recognition, loop detection, bundle adjustment, etc. The process is divided into three phases: short-term phase, medium-phase, and long-term phase. However, it is hard to access ORB-SLAM for users who are not familiar with Linux, computer vision, and Github. At the same time, the hardware like Realsense camera and IMU that ORBSLAM requires are hard to access. We create a streaming layer between iPhone and ORBSLAM on Ubuntu, so that everyone can play with the state-of-the-art SLAM via iPhone and a PC with pre-installed ORB-SLAM. This is a final project for course EECE5554: Robotics: Navigation and Sensing in Northeastern University. It is developed by Chenghao Wang, Meishan Li, Mingxi Jia and Me. More about this project is in this GitLab Page. Link Here.
Apr 26, 2023
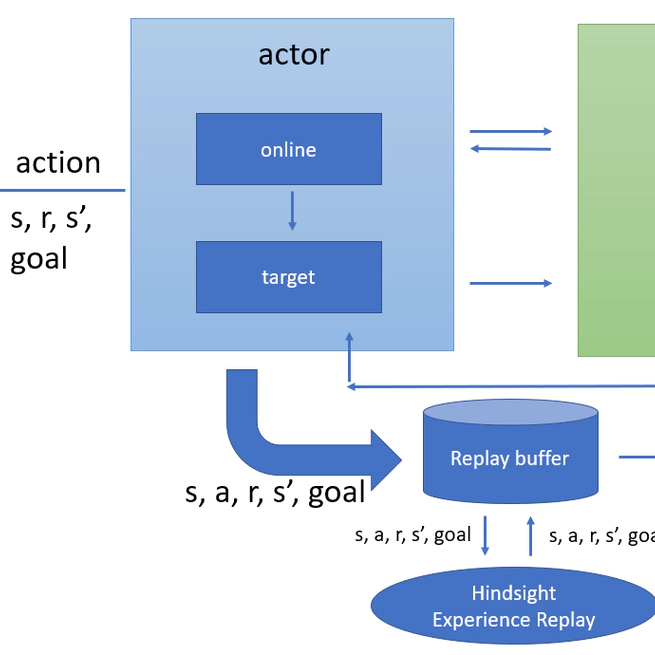
Improving Sample Efficiency of Robot Grasping
In goal-conditioned reinforcement learning problems, the sample efficiency is often a drawback that most of the explorations are not consider as very useful experience because they are failure episodes, which makes low sample efficiency. In this paper, we implemented a module of Hindsight Experience Replay (HER) in several goal-conditioned environments, to discover its utility of improving sample efficiency. Based on Deep Deterministic Policy Gradient (DDPG), the experiments showed that the HER module helps the agent learn much faster with more robustness. We then discussed about the limitation of HER and how hyper parameters effects its performance. This is a final project for course CS5180: Reinforcement Learning and Sequential Decision Making in Northeastern University. It is developed by me and Mingxi Jia. More details could be viewed in our pdf report.
Oct 31, 2022
SharkPulse
In goal-conditioned reinforcement learning problems, the sample efficiency is often a drawback that most of the explorations are not consider as very useful experience because they are failure episodes, which makes low sample efficiency. In this paper, we implemented a module of Hindsight Experience Replay (HER) in several goal-conditioned environments, to discover its utility of improving sample efficiency. Based on Deep Deterministic Policy Gradient (DDPG), the experiments showed that the HER module helps the agent learn much faster with more robustness. We then discussed about the limitation of HER and how hyper parameters effects its performance. The code is linked Here. Our final report could be viewed at Here.
May 31, 2021